Thực hành Tìm kiếm Toàn văn trong SQL Server Full-text
Giới thiệu
Trong hầu hết các trường hợp, chúng tôi sẽ sử dụng các chỉ mục được nhóm và không được nhóm để giúp truy vấn nhanh hơn, nhưng các loại chỉ mục này có những hạn chế riêng và không thể được sử dụng để tra cứu văn bản nhanh. Chẳng hạn, toán tử LIKE sẽ dẫn SQL Server quét toàn bộ bảng để chọn các giá trị đáp ứng biểu thức bên cạnh toán tử này. Điều này có nghĩa là nó sẽ không nhanh trong mọi trường hợp, ngay cả khi một chỉ mục được tạo cho cột được xem xét.
Microsoft SQL Server đưa ra câu trả lời cho một phần của vấn đề này với tính năng Tìm kiếm toàn văn bản. Tính năng này cho phép người dùng và ứng dụng chạy tra cứu dựa trên ký tự một cách hiệu quả bằng cách tạo một loại chỉ mục cụ thể được gọi là Chỉ mục Toàn văn. Chỉ mục này có thể được xây dựng trên đầu một hoặc nhiều cột cho một bảng cụ thể. Các cột này có thể thuộc các kiểu dữ liệu sau:
- ký tự ,
- véc ni ,
- nchar ,
- nvarchar ,
- văn bản ,
- văn bản ,
- hình ảnh ,
- xml ,
- varbinary (tối đa)
- TẬP HỒ SƠ
Việc xây dựng và sử dụng chỉ mục Toàn văn luôn được thực hiện trong ngữ cảnh ngôn ngữ cụ thể như tiếng Anh hoặc tiếng Pháp.
Trong các phần sau, trước tiên chúng ta sẽ dành chút thời gian để hiểu tổng quan về cách thức hoạt động của tính năng Tìm kiếm Toàn văn. Trong phần này, chúng ta sẽ định nghĩa một số khái niệm và sử dụng chúng để hiểu cách xây dựng và duy trì Chỉ mục toàn văn bản. Thậm chí chúng ta sẽ đi qua một ví dụ minh họa. Sau khi hoàn thành các khía cạnh lý thuyết, chúng ta sẽ tập trung vào một số khía cạnh thực tế để sử dụng và duy trì tính năng này: chúng ta sẽ xem cách tạo bảng được lập chỉ mục Toàn văn, cách liệt kê những bảng có Toàn văn lập chỉ mục và trên cột nào, v.v.
Các khái niệm
Các định nghĩa
Bây giờ chúng ta đã biết mục đích của tính năng Tìm kiếm toàn văn bản là gì, hãy đầu tư thời gian để hiểu cách thức hoạt động của tính năng này. Điều này sẽ giúp chúng tôi quản lý tính năng này.
Lưu ý rằng, khi cài đặt SQL Server, chúng ta có thể nói rằng tính năng này đặc biệt vì trình cài đặt xác định một dịch vụ daemon có tên là “fdhost.exe”. Quá trình này sẽ được gọi sau đây là “máy chủ daemon bộ lọc“.
Nó được bắt đầu bởi một trình khởi chạy dịch vụ có tên MSSQLFDLauncher vì những lo ngại về bảo mật. Nó sẽ trao đổi dữ liệu với dịch vụ SQL Server (sqlservr.exe) thông qua bộ nhớ dùng chung hoặc một đường dẫn có tên. Quá trình Fdhost.exe sẽ truy cập, lọc và mã hóa dữ liệu người dùng để thực sự xây dựng các chỉ mục Toàn văn. Nó cũng được gọi để phân tích các truy vấn Toàn văn, bao gồm ngắt từ và bắt đầu từ (xem bên dưới để biết thêm thông tin).
Điều này có nghĩa là toàn bộ tính năng Tìm kiếm Toàn văn được trải rộng trên hai quy trình này: fdhost.exe và sqlserv.exe và một số thành phần của tính năng này tương tác với nhau. Hãy xem xét các thành phần này:
- Bảng người dùng – (sqlserv.exe) – bảng có chỉ mục toàn văn.
- Trình thu thập toàn văn bản – trong sqlserv.exe – một luồng chịu trách nhiệm lên lịch và thúc đẩy dân số chỉ mục để theo dõi.
- Tệp từ điển đồng nghĩa – (sqlserv.exe)– tệp chứa từ đồng nghĩa của cụm từ tìm kiếm.
- Danh sách dừng – trong sqlserv.exe – các đối tượng chứa danh sách các từ phổ biến có thể bỏ qua vì chúng không quan trọng đối với tra cứu (ví dụ: « và », « hoặc », « nhưng »)
- Chuỗi bộ xử lý truy vấn – (sqlserv.exe)– chuỗi biên dịch và thực thi các truy vấn T-SQL và gửi tìm kiếm Toàn văn bản tới Công cụ toàn văn bản hai lần: một lần khi biên dịch và một lần trong khi thực hiện truy vấn. Kết quả truy vấn được khớp với chỉ mục toàn văn.
- Full-Text Engine – (sqlserv.exe)– có thể được coi là một phần của Bộ xử lý truy vấn. Nó biên dịch và chạy các truy vấn toàn văn bản, đồng thời tính đến các tệp danh sách dừng và từ điển đồng nghĩa trước khi gửi lại các tập kết quả cho các truy vấn này.
- Trình lập chỉ mục toàn văn bản – (sqlserv.exe)– Chủ đề này xây dựng cấu trúc được sử dụng để lưu trữ mã thông báo chỉ mục.
- Filter Daemon Manager – (sqlserv.exe)– luồng này giám sát trạng thái của dịch vụ daemon fdhost.exe.
- Luồng trình xử lý giao thức – (fdhost.exe) – luồng này lấy dữ liệu từ bộ nhớ để xử lý thêm và truy cập dữ liệu từ bảng người dùng.
- Bộ lọc – (fdhost.exe) – chúng cụ thể theo loại tài liệu và cho phép trích xuất dữ liệu văn bản từ nhiều loại dữ liệu khác nhau như varbinary, hình ảnh hoặc xml. Chẳng hạn, chúng sẽ được sử dụng để xóa mọi định dạng được nhúng trên văn bản của tài liệu MS Word. Bạn có thể chạy truy vấn sau để có cái nhìn tổng quan về các bộ lọc được xác định theo mặc định:
123EXEC sp_help_fulltext_system_components 'filter';
- Bộ ngắt từ và trình ngắt từ (fdhost.exe) – Mỗi ngôn ngữ có bộ ngắt từ riêng. Các thành phần này giúp tìm ra ranh giới của từng từ trong một câu dựa trên các quy tắc từ vựng của ngôn ngữ liên quan. Vì vậy, họ giúp tokenizing câu. Hơn nữa, mỗi bộ ngắt từ được sử dụng cùng với một thành phần gốc. Thành phần này giúp tìm gốc của động từ (dạng biến tố của nó) và chia động từ, cũng dựa trên các quy tắc dành riêng cho ngôn ngữ. Chẳng hạn, nó sẽ coi tất cả các dạng này là giống nhau: “viết”, “đã viết”, “nhà văn” đều là các dạng của từ “viết”. Các từ được xác định bởi một trong hai thành phần này được chèn dưới dạng từ khóa vào chỉ mục toàn văn.
Kiến trúc của một chỉ mục toàn văn bản
Trước hết, chúng ta phải biết rằng mọi chỉ mục toàn văn đều được lưu trữ trong cái mà Microsoft gọi là “danh mục toàn văn”. Nó giống như một thùng chứa các chỉ mục Toàn văn. Tại sao Microsoft xác định vùng chứa hợp lý cho các chỉ mục Toàn văn? Đơn giản vì các chỉ mục này thường được phân chia trên nhiều bảng nội bộ được gọi là các đoạn chỉ mục toàn văn bản. Những đoạn này được tạo khi chúng tôi chèn hoặc cập nhật bản ghi.
Chúng tôi có thể lấy lại dữ liệu về Chỉ mục toàn văn bằng cách sử dụng các chức năng và chế độ xem quản lý động. Một trong số đó là hàm sys.dm_fts_index_keywords_by_document . Nó trả về một tập dữ liệu với các cột sau:
- Một đại diện thập lục phân của từ khóa
- Một đại diện có thể đọc được của con người của từ khóa
- Mã định danh của cột tuân theo Chỉ mục toàn văn
- Mã định danh của tài liệu hoặc hàng mà từ khóa hiện tại đã được lập chỉ mục
- Số lần từ khóa này được tìm thấy trong tài liệu hoặc hàng đó được chỉ định bởi cột trước đó
Đây là một bộ kết quả mẫu:

Trong tập kết quả đó, chúng ta có thể thấy rằng đối với tài liệu có mã định danh là “14536” thì có 3 lần xuất hiện của từ khóa “%)”.
Điều này cho phép chúng tôi biết rằng một chỉ mục Toàn văn là một “ chỉ mục đảo ngược ” vì nó được tạo từ một nguồn dữ liệu nhất định và ánh xạ kết quả của việc tạo này trở lại nguồn dữ liệu của nó. Chúng ta cũng có thể nhận thấy rằng nó tính toán số liệu thống kê nhanh chóng về số lần xuất hiện. Nếu chúng tôi kiểm tra tài liệu DMV toàn văn , chúng tôi sẽ nhận thấy rằng có thể thu được những số liệu thống kê này:
- bằng tài liệu,
- theo tài sản,
- bằng từ khóa.
Điều này có nghĩa là một chỉ mục Toàn văn không thực sự có thể so sánh được với một chỉ mục thông thường. Nhưng đó không phải là sự khác biệt duy nhất:
- Chúng tôi chỉ có thể xác định một chỉ mục Toàn văn cho mỗi bảng trong khi chúng tôi có thể xác định nhiều chỉ mục cho các chỉ mục bình thường.
- Việc thêm dữ liệu vào chỉ mục Toàn văn được gọi là dân số . Ngược lại với các chỉ mục thông thường, các quần thể này không phải là một phần của giao dịch. Điều này có nghĩa là mặc dù dữ liệu đã được chèn vào bảng được lập chỉ mục Toàn văn, điều này xảy ra khi giao dịch chèn những dữ liệu này được thực hiện, điều này không nhất thiết có nghĩa là chỉ mục Toàn văn đã được cập nhật. Dân số chỉ mục toàn văn bản là không đồng bộ.
- Không có nhóm các chỉ mục thông thường vào một danh mục chỉ mục.
Cách chỉ mục toàn văn bản được điền
Khi tập hợp chỉ mục không đồng bộ, điều gì cho SQL Server biết đã đến lúc thực sự bắt đầu tập hợp? Trên thực tế, có một tùy chọn được gọi là “Theo dõi thay đổi”, có thể được định cấu hình bằng Chỉ mục toàn văn bản và có một số giá trị có thể có:
- AUTO : yêu cầu SQL Server theo dõi các thay đổi dữ liệu cho một bảng và tự động yêu cầu dân số lập chỉ mục
- THỦ CÔNG : yêu cầu SQL Server theo dõi các thay đổi dữ liệu cho một bảng nhưng để người dùng tự yêu cầu dân số chỉ mục. Điều này có nghĩa là có thể mất vài giờ hoặc vài ngày trước khi Toàn văn được cập nhật
- TẮT : có nghĩa là SQL Server sẽ không theo dõi các thay đổi dữ liệu và việc duy trì chỉ mục này được thực hiện hoàn toàn thủ công. Trên các hệ thống sử dụng rộng rãi tính năng này, chế độ này cuối cùng có thể yêu cầu các khoảng thời gian bảo trì lớn vì mọi người sẽ phải kiểm tra việc đọc tất cả các bảng.
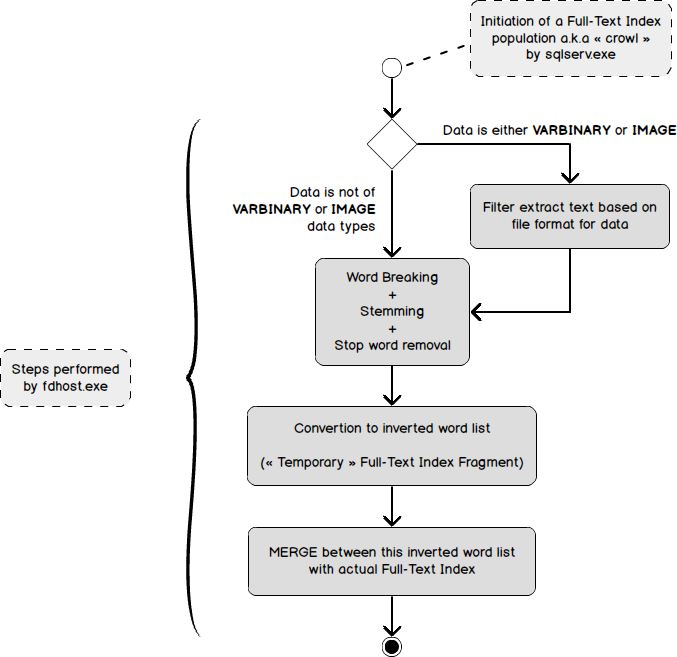
Bạn sẽ tìm thấy bên dưới một sơ đồ tóm tắt cách một Chỉ mục toàn văn bản phải được điền (lần đầu tiên hoặc dựa trên hoạt động của người dùng) chỉ với một bản ghi mới hoặc được cập nhật.
Có một điều quan trọng cần lưu ý: tập hợp chỉ mục được bắt đầu bởi sqlserv.exe và tập hợp thực sự được thực hiện bởi fdhost.exe. Như đã thảo luận ở trên, tập hợp này sẽ không xảy ra mỗi khi người dùng tạo hoặc thay đổi bản ghi trong bảng được lập chỉ mục Toàn văn. Thay vào đó, khi tính năng theo dõi thay đổi ở chế độ TỰ ĐỘNG, chuỗi Trình thu thập toàn văn bản (bên trong sqlserv.exe) sẽ yêu cầu fdhost.exe bắt đầu tập hợp chỉ mục. Đây là một phần giải thích tại sao quy trình tổng hợp chỉ mục không đồng bộ với các sửa đổi dữ liệu.
Dân số Chỉ mục toàn văn bằng ví dụ
Giả sử chúng ta có một bảng có tên là MyDocs với hai cột, một có tên là DocId xác định duy nhất một bản ghi và một có tên là Nhận xét chứa nhận xét về tài liệu ở dạng văn bản thuần túy, do đó, đó là cột VARCHAR .
Bây giờ, giả sử bảng này có ba bản ghi như sau:
| ID tài liệu | Bình luận |
| 1 | Cuốn sách hay nhất từng có trên Full-Text Index |
| 2 | Tài nguyên tuyệt vời trên các chỉ mục và bảng |
| 3 | Hội thảo thú vị về Toàn văn |
Bây giờ, giả sử rằng chúng ta đã tạo một Chỉ mục toàn văn bản trên bảng đó và SQL Server quyết định rằng đã đến lúc điền nó.
Trước tiên, nó sẽ xử lý hàng có giá trị 1 cho cột DocId . Nó sẽ mã hóa nội dung của cột Nhận xét và bắt đầu xây dựng một đoạn chỉ mục ánh xạ từng mã thông báo tới bản ghi này như sau:
| từ khóa | ID tài liệu |
| tốt nhất | 1 |
| sách | 1 |
| bao giờ | 1 |
| TRÊN | 1 |
| toàn văn | 1 |
| mục lục | 1 |
Sau đó, nó sẽ cắt “full-text” thành “full” và “text” và loại bỏ từ khóa “on” vì nó là stop word, chúng ta sẽ có danh sách từ khóa sau:
| từ khóa | ID tài liệu |
| tốt nhất | 1 |
| sách | 1 |
| bao giờ | 1 |
| Đầy | 1 |
| toàn văn | 1 |
| mục lục | 1 |
| Chữ | 1 |
Lưu ý : Lưu ý rằng chỉ mục được xây dựng theo thứ tự bảng chữ cái
Nó sẽ làm tương tự với tài liệu thứ hai để danh sách từ khóa sẽ bao gồm: “mát mẻ”, “chỉ mục”, “tài nguyên” và “bảng”. Sau đó, nó sẽ phân tích cột Nhận xét cho tài liệu thứ ba và xây dựng danh sách từ khóa sau: “thú vị”, “Toàn văn”, “Đầy đủ”, “Văn bản” và “hội thảo”.
Kết quả phân tích cho mỗi tài liệu có thể dẫn đến việc tạo ra một đoạn chỉ mục. Nếu chúng ta đặt chúng lại với nhau, chúng ta có danh sách từ khóa sau:
| từ khóa | ID tài liệu | # lần xuất hiện |
| tốt nhất | 1 | 1 |
| sách | 1 | 1 |
| Mát mẻ | 2,3 | 2 |
| bao giờ | 1 | 1 |
| Đầy | 1,3 | 2 |
| toàn văn | 1,3 | 2 |
| mục lục | 1 | 1 |
| chỉ mục | 2 | 1 |
| Nguồn | 2 | 1 |
| Những cái bàn | 2 | 1 |
| Chữ | 1,3 | 2 |
| Xưởng | 3 | 1 |
Danh sách trên sẽ là dữ liệu thực được lưu trữ trong chỉ mục Toàn văn của chúng tôi khi bảng trống. Bạn có thể kiểm tra xem đây thực sự là những gì bạn nhận được bằng cách chạy mã trong Phụ lục A của bài viết này. Tuy nhiên, bạn nên đọc hết bài viết này trước khi đi thẳng vào phần phụ lục này !
Cách tạo bảng có bật Toàn văn
Giả sử chúng ta có một bảng có tên [dbo].[DM_OBJECT_FILE] đã được tạo bằng cách sử dụng câu lệnh sau.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
CREATE TABLE [dbo].[DM_OBJECT_FILE] (
[FILE_ID] [int] NOT NULL,
[FILE_FIN] [int] NOT NULL,
[FILE_TITLE] [Varchar] (255) ,
[OBJ_ID] [int] NOT NULL ,
[FILE_ATT] [smallint] NOT NULL,
[FILE_PATH] [Varchar] (500) NULL,
[FILE_EXT] [Varchar](50) NULL,
[FILE_TXT] [varbinary] (max) NULL,
[FILE_KEYWORDS] [Varchar] (1000) NULL,
[FILE_STATUS] [smallint] NULL,
[FILE_TXT_SIZE] [Int] default 0,
[OBJ_FILE_IDX_DOCTYPE] [Varchar] (3) Null,
CONSTRAINT [PK_DM_OBJECT_FILE] PRIMARY KEY CLUSTERED ([FILE_ID])
)
|
Mỗi tệp được nhập vào bảng đó được xác định duy nhất bởi cột FILE_ID , cột FILE_TXT đề cập đến nội dung của tệp này và OBJ_FILE_IDX_DOCTYPE đề cập đến loại tài liệu được lưu trữ trong cột FILE_TXT .
Bây giờ, chúng tôi sẵn sàng tạo Chỉ mục toàn văn bản trên bảng này. Điều này có nghĩa là tính năng Toàn văn đã được cài đặt trên phiên bản của chúng tôi. Để kiểm tra xem đó có phải là trường hợp hay không, chúng ta có thể sử dụng truy vấn sau:
|
1
2
3
4
5
6
7
8
|
SELECT
CASE FULLTEXTSERVICEPROPERTY('IsFullTextInstalled')
WHEN 1 THEN 'Full-Text installed.'
ELSE 'Full-Text is NOT installed.'
END
;
|
Nếu Full-Text chưa được cài đặt, bạn nên xem xét việc cài đặt nó trước.
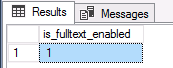
Ngay khi bạn chắc chắn rằng tính năng Toàn văn đã được cài đặt, chúng ta nên kiểm tra xem tìm kiếm Toàn văn đã được bật cho cơ sở dữ liệu nơi bảng của chúng ta được lưu trữ chưa. Chúng ta có thể kiểm tra nó bằng câu lệnh sau:
|
1
2
3
4
5
|
SELECT is_fulltext_enabled
FROM sys.databases
WHERE database_id = DB_ID()
|
Chúng ta sẽ nhận được đầu ra sau:
Nếu không, chúng ta nên chạy câu lệnh T-SQL sau:
|
1
2
3
|
exec sp_fulltext_database 'enable';
|
Nhưng đây không phải là kết thúc! Chúng tôi cũng muốn kiểm tra xem đã có một danh mục toàn văn chưa, là một đối tượng cơ sở dữ liệu ảo không thuộc bất kỳ nhóm tệp nào và đề cập đến một nhóm các chỉ mục Toàn văn. Để làm như vậy, chúng tôi sẽ chạy truy vấn sau:
|
1
2
3
4
|
select *
FROM sys.fulltext_catalogs
|
Nếu truy vấn này không trả về bất kỳ hàng nào, thì chúng ta phải tạo một hoặc nhiều danh mục toàn văn và đặt một trong số chúng làm mặc định. Để thực hiện hành động này, chúng ta sẽ sử dụng một câu lệnh dựa trên CREATE FULLTEXT CATALOG như sau:
|
1
2
3
|
CREATE FULLTEXT CATALOG FullTextCatalog AS DEFAULT;
|
Bây giờ, chúng ta đã sẵn sàng để tạo chỉ mục Toàn văn trên bảng [dbo].[DM_OBJECT_FILE] . Để tạo một chỉ mục như vậy, chúng ta phải có một số thông tin:
- Chỉ mục chính được sử dụng để xác định duy nhất các bản ghi là gì?
- Những cột nào nên là một phần của chỉ mục? (Ở đây: Cột FILE_TXT sẽ được sử dụng)
- Cột đại diện cho loại tài liệu nào và thông tin này được lưu trữ trong cột nào? (Ở đây: Cột OBJ_FILE_IDX_DOCTYPE sẽ được sử dụng)
- Ngôn ngữ nào được sử dụng trong cột này hoặc tốt hơn là nên hoàn toàn trung lập về việc giải thích ngôn ngữ?
- Chúng tôi có kích hoạt theo dõi thay đổi và để chỉ mục tự cập nhật hay chúng tôi tự quản lý phần này?
Bạn sẽ tìm thấy bên dưới câu lệnh tạo cho Chỉ mục toàn văn bản trên cột FILE_TXT từ bảng dbo.DM_OBJECT_FILE , với diễn giải ngôn ngữ trung lập, cập nhật tự động và không có danh sách dừng.
|
1
2
3
4
5
6
7
8
9
|
CREATE FULLTEXT INDEX ON dbo.DM_OBJECT_FILE (
FILE_TXT TYPE COLUMN OBJ_FILE_IDX_DOCTYPE LANGUAGE 0
) KEY INDEX PK_DM_OBJECT_FILE
WITH
CHANGE_TRACKING = AUTO,
STOPLIST=OFF
;
|
Cách thay đổi cấu hình của Chỉ mục toàn văn bản
Có một lệnh T-SQL tên là ALTER FULLTEXT INDEX cho phép chúng ta thực hiện một số thao tác trên Full-Text Index như:
- Bật hoặc tắt chỉ mục
- Bật hoặc tắt theo dõi thay đổi đối với dân số Chỉ mục Toàn văn. Nếu nó vẫn được bật, chúng tôi có thể cho SQL Server biết liệu có nên tự động lên lịch cho một tập hợp chỉ mục dựa trên hoạt động của người dùng hay để chúng tôi thực hiện thủ công.
- Thêm, sửa đổi hoặc chỉnh sửa danh sách các cột nên là một phần của Chỉ mục Toàn văn.
- Kiểm soát dân số chỉ mục (chỉ hữu ích khi chúng tôi không bật theo dõi thay đổi ở chế độ tự động)
Để biết thêm chi tiết, vui lòng tham khảo trang tài liệu của Microsoft .
Cách sử dụng Chỉ mục Toàn văn trong truy vấn
Khi mọi thứ đã sẵn sàng, Chỉ mục toàn văn bản của chúng tôi được tạo trên bảng của chúng tôi và chúng tôi có thể bắt đầu sử dụng nó với các chức năng tích hợp sẵn. Các chức năng sau đây là các chức năng vị ngữ. Điều này có nghĩa là nó trả về một giá trị Boolean có thể được sử dụng trong mệnh đề WHERE .
| Tên chức năng | Giải trình | ||
| CHỨA |
Tìm kiếm các kết quả khớp chính xác hoặc mờ (ít chính xác hơn) với các từ và cụm từ đơn lẻ, các từ trong một khoảng cách nhất định với nhau hoặc các kết quả khớp có trọng số trong SQL Server. Các loại tra cứu phù hợp:
Ví dụ sử dụng:
|
||
| VĂN BẢN MIỄN PHÍ |
Tìm kiếm các giá trị phù hợp với ý nghĩa chứ không chỉ từ ngữ chính xác của các từ trong điều kiện tìm kiếm. Chức năng này sẽ:
Ví dụ sử dụng:
|
||
| CHỨA ĐƯỢC |
Tra cứu tương tự như hàm CONTAINS ngoại trừ việc nó trả về một bảng gồm các hàng có các cột sau:
Cách sử dụng ví dụ đơn giản: tìm “blabla” hoặc “huh”
|
||
| BẢNG MIỄN PHÍ |
Trả về một bảng gồm 0, một hoặc nhiều hàng cho những cột chứa các kiểu dữ liệu dựa trên ký tự cho các giá trị khớp với ý nghĩa, nhưng không khớp với từ ngữ chính xác của văn bản trong cột đã chỉ định. Cách sử dụng ví dụ đơn giản: tìm “blabla” hoặc “huh”
|
Dưới đây là so sánh về số lượng kết quả giữa các vị từ CONTAINSTABLE và FREETEXTTABLE bằng cách sử dụng ví dụ ở trên.
Đầu tiên, kết quả của CONTAINSTABLE :

Thứ hai, kết quả của FREETEXTTABLE :
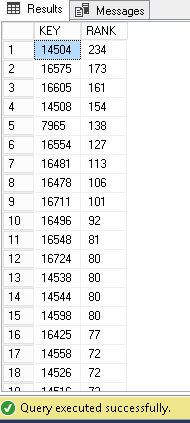
Như chúng ta có thể thấy, đối với cái đầu tiên, chúng tôi chỉ nhận lại 13 hàng và giá trị xếp hạng không cao trong khi cái thứ hai trả về nhiều hơn 17 hàng và giá trị xếp hạng cao hơn. Hơn nữa, chúng ta có thể kiểm tra xem thứ tự của các phím có khác nhau không: Phím 16575 nằm ở vị trí thứ tư trong ảnh chụp màn hình đầu tiên trong khi nó ở vị trí thứ hai trong ảnh chụp màn hình thứ hai.
Các chức năng vị từ này có thể được sử dụng rộng rãi và không giới hạn đối với các tra cứu cố định. Thay vào đó, có chức năng ngữ pháp mở rộng liên quan đến tham số tra cứu của nó. Trên mỗi trang tài liệu dành cho các chức năng này, chúng ta sẽ tìm thấy định nghĩa của <chứa_điều_kiện_tìm_kiếm> trong định nghĩa ngữ pháp của hàm. Nếu chúng ta xem xét kỹ ngữ pháp này, chúng ta có thể thấy rằng nó rất phong phú và chúng ta phải học điều này để tận dụng tối đa tính năng Tìm kiếm Toàn văn!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
<contains_search_condition> ::=
{ <simple_term>
| <prefix_term>
| <generation_term>
| <generic_proximity_term>
| <custom_proximity_term>
| <weighted_term>
}
| { ( <contains_search_condition> )
{ { AND | & } | { AND NOT | &! } | { OR | | } }
<contains_search_condition> [ ...n ]
}
<simple_term> ::=
{ word | "phrase" }
<prefix term> ::=
{ "word*" | "phrase*" }
<generation_term> ::=
FORMSOF ( { INFLECTIONAL | THESAURUS } , <simple_term> [ ,...n ] )
<generic_proximity_term> ::=
{ <simple_term> | <prefix_term> } { { { NEAR | ~ }
{ <simple_term> | <prefix_term> } } [ ...n ] }
<custom_proximity_term> ::=
NEAR (
{
{ <simple_term> | <prefix_term> } [ ,…n ]
|
( { <simple_term> | <prefix_term> } [ ,…n ] )
[, <maximum_distance> [, <match_order> ] ]
}
)
<maximum_distance> ::= { integer | MAX }
<match_order> ::= { TRUE | FALSE }
<weighted_term> ::=
ISABOUT
( { {
<simple_term>
| <prefix_term>
| <generation_term>
| <proximity_term>
}
[ WEIGHT ( weight_value ) ]
} [ ,...n ]
)
|
Ngoài ra, các hàm khác trả về bảng đã được thêm vào từ SQL Server 2012. Đó là:
Tìm kiếm thông tin liên quan đến tính năng Full-Text
Cách lấy danh sách các ngôn ngữ được hỗ trợ
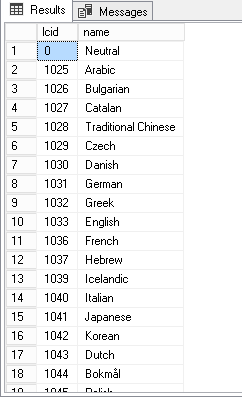
Chúng tôi có thể chạy truy vấn sau để lấy lại danh sách các ngôn ngữ được hỗ trợ và mã định danh ngôn ngữ của chúng:
|
1
2
3
4
5
|
SELECT *
FROM sys.fulltext_languages
ORDER BY lcid
|
Đây là một mẫu của tập hợp kết quả:
Cách lấy danh sách các chỉ mục Toàn văn trong một cơ sở dữ liệu cụ thể
Giả sử chúng ta muốn liệt kê những bảng và cột nào được sử dụng với tính năng Toàn văn. Để làm như vậy, chúng ta có thể chạy truy vấn sau:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECT
SCHEMA_NAME(tbl.schema_id) as SchemaName,
tbl.name AS TableName,
FT_ctlg.name AS FullTextCatalogName,
i.name AS UniqueIndexName,
scols.name AS IndexedColumnName
FROM
sys.tables tbl
INNER JOIN
sys.fulltext_indexes FT_idx
ON
tbl.[object_id] = FT_idx.[object_id]
INNER JOIN
sys.fulltext_index_columns FT_idx_cols
ON
FT_idx_cols.[object_id] = tbl.[object_id]
INNER JOIN
sys.columns scols
ON
FT_idx_cols.column_id = scols.column_id
AND FT_idx_cols.[object_id] = scols.[object_id]
INNER JOIN
sys.fulltext_catalogs FT_ctlg
ON
FT_idx.fulltext_catalog_id = FT_ctlg.fulltext_catalog_id
INNER JOIN
sys.indexes i
ON
FT_idx.unique_index_id = i.index_id
AND FT_idx.[object_id] = i.[object_id];
|
Đây là một kết quả mẫu:

Cách kiểm tra kết quả phân tích toàn văn
Có hai cách để kiểm tra xem tính năng Toàn văn phân tích cú pháp một văn bản nhất định như thế nào tùy thuộc vào nguồn của văn bản.
Nguồn của văn bản là một Chuỗi
Nếu bạn muốn kiểm tra nhanh những từ khóa bạn sẽ nhận được cho một chuỗi cụ thể, bạn có thể muốn sử dụng hàm tích hợp sẵn sys.dm_fts_parser .
Đây là một ví dụ về cuộc gọi đến chức năng đó.
- Tham số đầu tiên là chuỗi phải được phân tích cú pháp.
- Tham số thứ hai là định danh ngôn ngữ. Ở đây, nó được đặt thành 0, có nghĩa là nó trung tính.
- Tham số hhird là định danh của danh sách dừng. Ở đây không có danh sách dừng được sử dụng.
- Tham số cuối cùng cho biết chức năng này có nhạy cảm hay không với dấu trọng âm. Ở đây, chúng tôi yêu cầu vô cảm.
Nói cách khác, chức năng này sẽ lấy thông tin bạn sẽ cung cấp khi tạo Chỉ mục Toàn văn.
|
1
2
3
4
5
6
7
8
|
select * from sys.dm_fts_parser(
'" dsolkjfdskljfsd dfsd-MMM-236.127 dojfdslfkjds"',
0,
NULL,
0
) ;
|
Đây là kết quả tương ứng. Chúng ta có thể thấy rằng từ dòng đơn giản này, chúng ta có nhiều từ khóa được tạo:
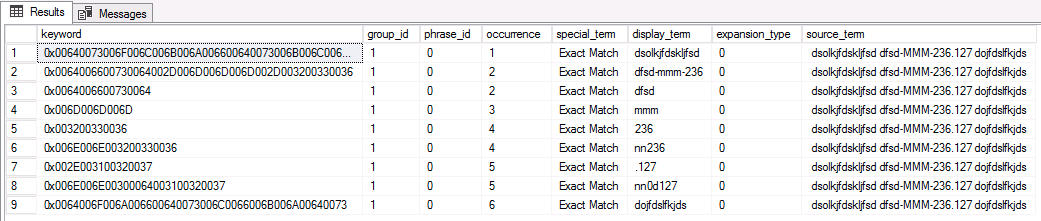
Nguồn của văn bản là một Chỉ mục Toàn văn
Nếu một bảng đã được tạo bằng chỉ mục Toàn văn, chúng tôi sẽ sử dụng một chức năng quản lý động (DMF) khác có tên là sys.dm_fts_index_keywords nhận làm tham số:
- Mã định danh cơ sở dữ liệu mà nó sẽ xem xét
- Mã định danh đối tượng trong cơ sở dữ liệu đó
Nó trả về một tập dữ liệu với biểu diễn thập lục phân của từ khóa, dạng tương ứng của nó trong văn bản thuần túy, mã định danh của cột trong đó từ khóa đã được tìm thấy và cuối cùng là số lượng tài liệu có thể tìm thấy từ khóa này.
Bạn sẽ tìm thấy bên dưới một truy vấn T-SQL để lấy lại các từ khóa được tìm thấy bởi tính năng Toàn văn trong bảng dbo.DM_OBJECT_FILE của chúng tôi để kết quả được đặt.
|
1
2
3
4
|
select *
From sys.dm_fts_index_keywords(DB_ID(),OBJECT_ID('dbo.DM_OBJECT_FILE'))
|

Cách duy trì Chỉ mục toàn văn bản với theo dõi thay đổi ở chế độ TỰ ĐỘNG
Nếu bạn là DBA, bạn không thể bỏ qua câu hỏi bảo trì cho các chỉ mục cụ thể này là các chỉ mục Toàn văn. Ngoại trừ các hệ thống lớn, tôi nghĩ không có lý do gì để đặt theo dõi thay đổi sang chế độ khác ngoài AUTO . Đó là lý do tại sao chúng tôi sẽ chỉ đề cập đến chế độ này.
Trên thực tế, rất khó để có được những khuyến nghị tốt về cách chúng ta nên làm điều này. Ví dụ: tôi chưa tìm thấy quy tắc nào từ Microsoft nói rằng “nếu có 10% phân mảnh thì tổ chức lại, nếu hơn 30% thì xây dựng lại chỉ mục”, đây là nguyên tắc phổ biến để bảo trì chỉ mục thông thường.
Sau khi đọc đoạn văn trên, có những câu hỏi sẽ xuất hiện:
- Làm thế nào để chúng tôi xây dựng lại một chỉ mục toàn văn bản?
- Chỉ mục Toàn văn có thể bị phân mảnh không?
- Nếu vậy, làm thế nào chúng ta có thể nhận được một số chi tiết về điều này?
- Sau khi chúng tôi có thông tin chi tiết về vấn đề này, làm thế nào để xác định khi nào cần thực hiện hành động khắc phục?
Làm cách nào để sắp xếp lại hoặc xây dựng lại một chỉ mục Toàn văn cụ thể?
Không có khả năng sắp xếp lại hoặc xây dựng lại một chỉ mục Toàn văn đã cho ngoại trừ bằng cách loại bỏ và tạo lại nó, sử dụng các lệnh DROP FULLTEXT INDEX và CREATE FULLTEXT INDEX .
Tuy nhiên, hãy nhớ rằng các chỉ mục này được nhóm vào một thùng chứa hợp lý được gọi là danh mục Toàn văn. Mặc dù chúng ta không thể xây dựng lại hoặc sắp xếp lại một chỉ mục cụ thể, nhưng chúng ta có thể thực hiện việc đó trên danh mục Toàn văn bằng cách sử dụng lệnh ALTER FULLTEXT CATALOG T-SQL.
|
1
2
3
4
5
6
7
|
ALTER FULLTEXT CATALOG catalog_name
{ REBUILD [ WITH ACCENT_SENSITIVITY = { ON | OFF } ]
| REORGANIZE
| AS DEFAULT
}
|
Chỉ mục Toàn văn có thể bị phân mảnh không?
Câu trả lời cho câu hỏi này khá rõ ràng như chúng tôi đã nói rằng, theo thiết kế, chỉ mục Toàn văn được xây dựng bằng cách sử dụng các đoạn chỉ mục được tạo trong quá trình tổng hợp chỉ mục (hoặc thu thập thông tin chỉ mục). Điều này có nghĩa là, vâng, các chỉ mục Toàn văn có thể bị phân mảnh và mức độ phân mảnh cao rõ ràng sẽ có tác động trực tiếp đến hiệu suất của ứng dụng.
Làm cách nào để kiểm tra phân mảnh chỉ mục Toàn văn?
Microsoft cung cấp một tập hợp các bảng hoặc dạng xem quản lý mà chúng ta có thể truy vấn để có được cái nhìn tổng quan về phân mảnh chỉ mục Toàn văn bản. Đó là:
- sys.fulltext_catalogs để lấy danh sách Danh mục toàn văn
- sys.fulltext_indexes để lấy danh sách Chỉ mục Toàn văn
- sys.fulltext_index_fragments để lấy danh sách các đoạn chỉ mục
Chúng ta có thể kết hợp dữ liệu từ các đối tượng quản lý này để lấy lại cái nhìn tổng quan về:
- Chỉ mục nào nằm trong Danh mục toàn văn nào?
- Chỉ mục Toàn văn chiếm bao nhiêu dung lượng?
- Chỉ mục Toàn văn dựa trên đối tượng nào?
- Mức độ quan trọng của sự phân mảnh (về kích thước (Mb) và phần trăm)
Điều này có thể được thực hiện bằng cách sử dụng truy vấn sau đây, đây là bản chuyển thể của truy vấn được xuất bản bởi Geoff Patterson trên StackExchange:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
WITH FragmentationDetails
AS (
SELECT
table_id,
COUNT(*) AS FragmentsCount,
CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS IndexSizeMb,
CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mb
FROM sys.fulltext_index_fragments
GROUP BY table_id
)
SELECT
DB_NAME() AS DatabaseName,
ftc.fulltext_catalog_id AS CatalogId,
ftc.[name] AS CatalogName,
fti.change_tracking_state AS ChangeTrackingState,
fti.object_id AS BaseObjectId,
QUOTENAME(OBJECT_SCHEMA_NAME(fti.object_id)) + '.' + QUOTENAME(OBJECT_NAME(fti.object_id)) AS BaseObjectName,
f.IndexSizeMb AS IndexSizeMb,
f.FragmentsCount AS FragmentsCount,
f.largest_fragment_mb AS IndexLargestFragmentMb,
f.IndexSizeMb - f.largest_fragment_mb AS IndexFragmentationSpaceMb,
CASE
WHEN f.IndexSizeMb = 0 THEN 0
ELSE
100.0 * (f.IndexSizeMb - f.largest_fragment_mb) / f.IndexSizeMb
END AS IndexFragmentationPct
FROM
sys.fulltext_catalogs ftc
JOIN
sys.fulltext_indexes fti
ON
fti.fulltext_catalog_id = ftc.fulltext_catalog_id
JOIN FragmentationDetails f
ON f.table_id = fti.object_id
;
|
Đây là một kết quả mẫu. Để dễ đọc hình ảnh, các hàng đã được chia thành hai bộ:

Khi nào chúng ta cần thực hiện các hành động khắc phục?
Tôi chưa thấy bất kỳ đề xuất nào về điều này trên trang web tài liệu của Microsoft nhưng đây là kết quả tìm kiếm của tôi:
- Dựa trên các nghiên cứu của Geoff Patterson , ông đã xác định rằng Chỉ mục toàn văn bản cần được xây dựng lại bắt đầu từ 10% phân mảnh.
- Trong bài đăng trên blog của mình , Barry Kind đề xuất tổ chức lại danh mục Toàn văn khi đạt được 30 đến 50 đoạn trên mỗi bảng.
Có một số thử nghiệm phải được thực hiện để tìm ra bộ tiêu chí phù hợp nhưng chúng sẽ không được đề cập trong bài viết này.
Bài viết tiếp theo trong loạt bài này:
Phụ lục A – mã để tạo bảng testing.MyDocs
Bạn sẽ tìm thấy bên dưới các hướng dẫn T-SQL cho phép bạn kiểm tra các kết quả mà chúng tôi đã công bố trong phần Dân số chỉ mục toàn văn bản theo ví dụ .
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
create schema testing;
DROP TABLE testing.MyDocs;
create table testing.MyDocs (
DocId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_MyDocs PRIMARY KEY,
Comments VARCHAR(MAX)
);
insert into testing.MyDocs (comments)
values
('Best book ever on Full-Text Index'),
('Cool resource on indexes and tables'),
('Cool workshop on Full-Text')
;
CREATE FULLTEXT INDEX ON testing.MyDocs(
Comments LANGUAGE 1033 /* English */
) KEY INDEX PK_MyDocs
;
select * From sys.dm_fts_index_keywords_by_document(DB_ID(DB_NAME()),OBJECT_ID('testing.MyDocs'))
--where document_id = 3
;
select * From sys.dm_fts_index_keywords(DB_ID(DB_NAME()),OBJECT_ID('testing.MyDocs'))
-- cleanups
DROP TABLE testing.MyDocs
DROP SCHEMA testing;
|